Cloud-Optimized Geospatial Formats Overview
These slides are a summarization of Cloud-Optimized Geospatial Formats Guide to support presentations.
What Makes Cloud-optimized Challenging?
What Makes Cloud-optimized Challenging?
There is no one-size-fits-all packaging for data, as the optimal packaging is highly use-case dependent.
Task 51 - Cloud-Optimized Format Study
Authors: Chris Durbin, Patrick Quinn, Dana Shum
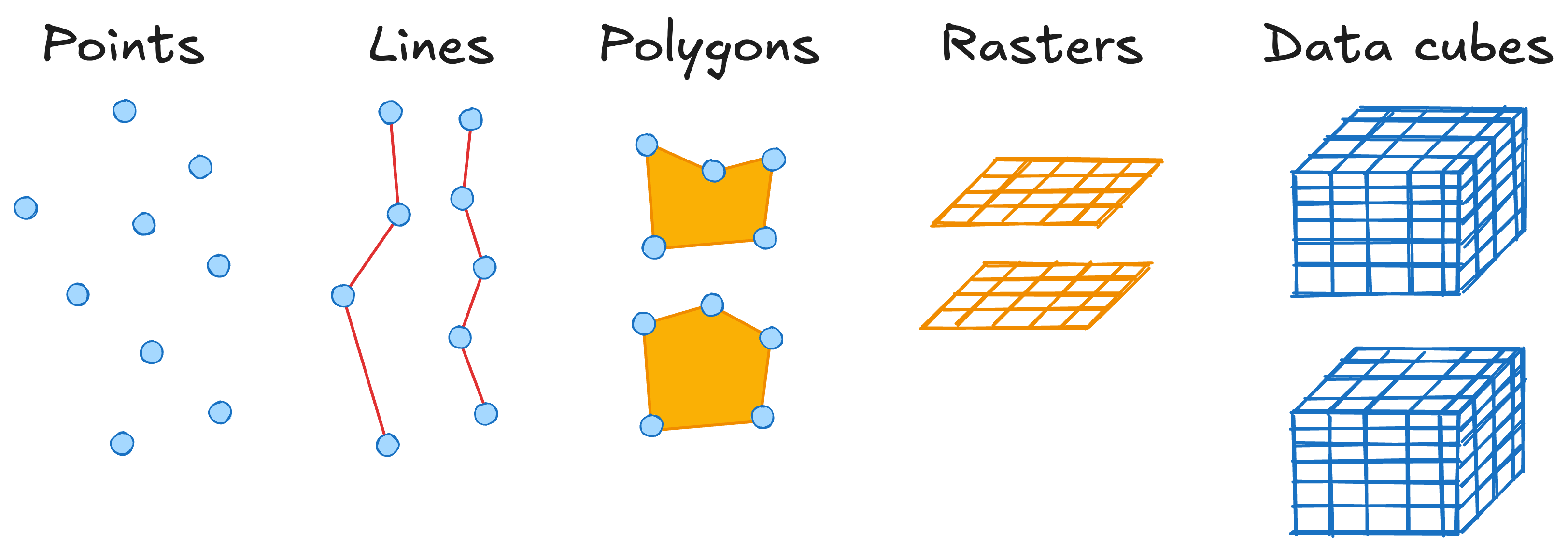
What Does Cloud-Optimized Mean?
- Accessible over HTTP using range requests.
- This makes it compatible with object storage (a file storage alternative to local disk) and thus accessible via HTTP, from many compute instances.
- Supports lazy access and intelligent subsetting.
- Integrates with high-level analysis libraries and distributed frameworks.
What are COGs?
- COGs are raster data representing a snapshot in time of gridded data, for example digital elevation models (DEMs).
- COGs are a de facto standard, with an Open Geospatial Consortium (OGC) standard under review.
- The standard specifies conformance to how the GeoTIFF is formatted, with additional requirements of tiling and overviews.
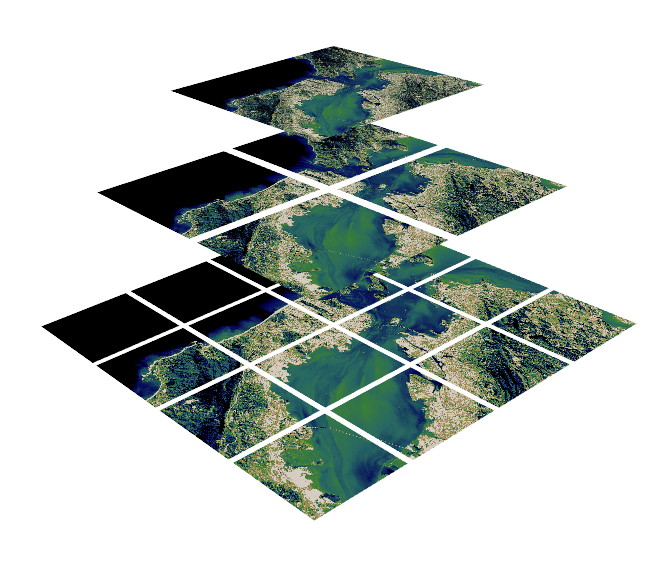
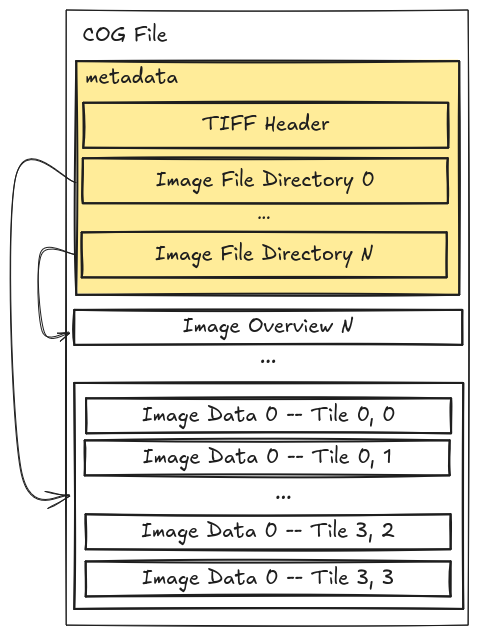
What are COGs?
- COGs have internal file directories (IFDs) which are used to tell clients where to find different overview levels and data within the file.
- Clients can use this metadata to read only the data they need to visualize or calculate.
- This internal organization is friendly for consumption by clients issuing HTTP GET range request (“bytes: start_offset-end_offset” HTTP header)
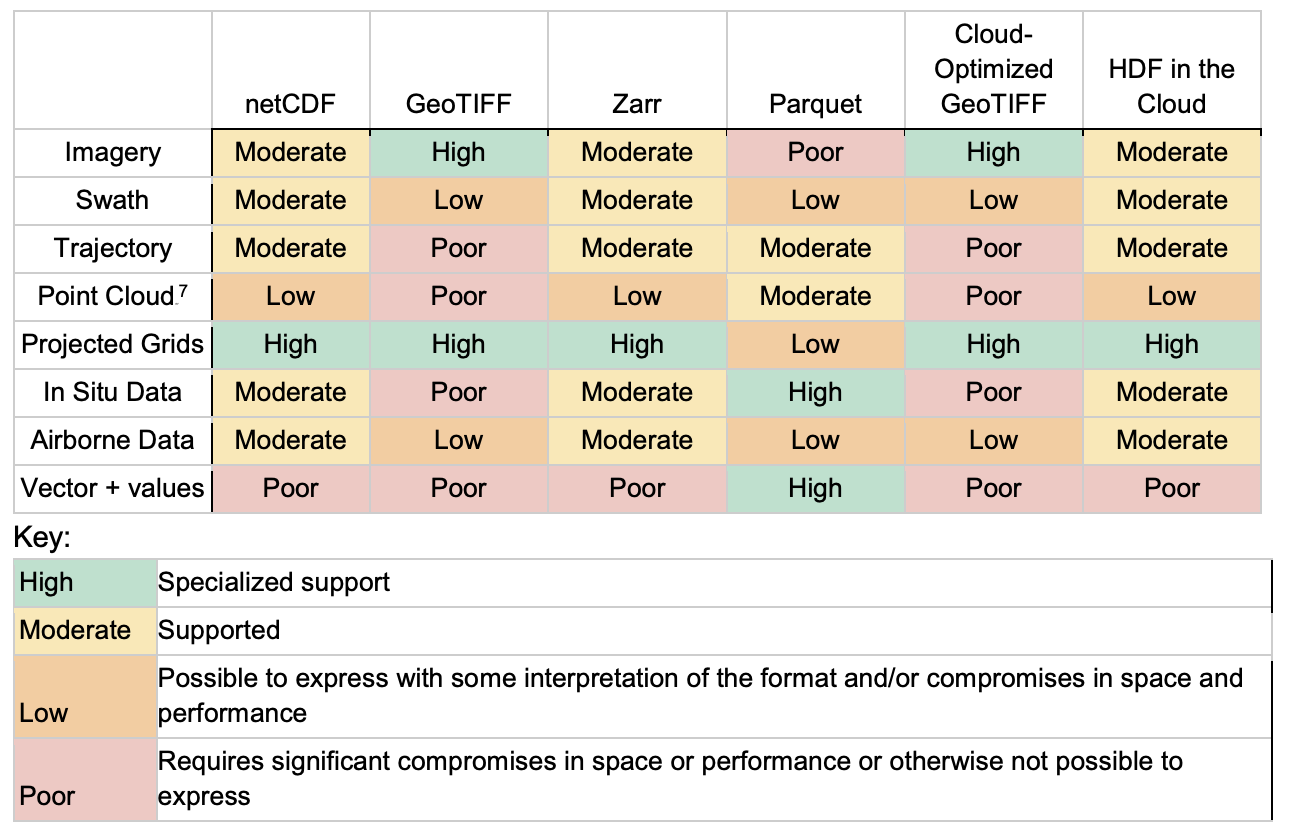
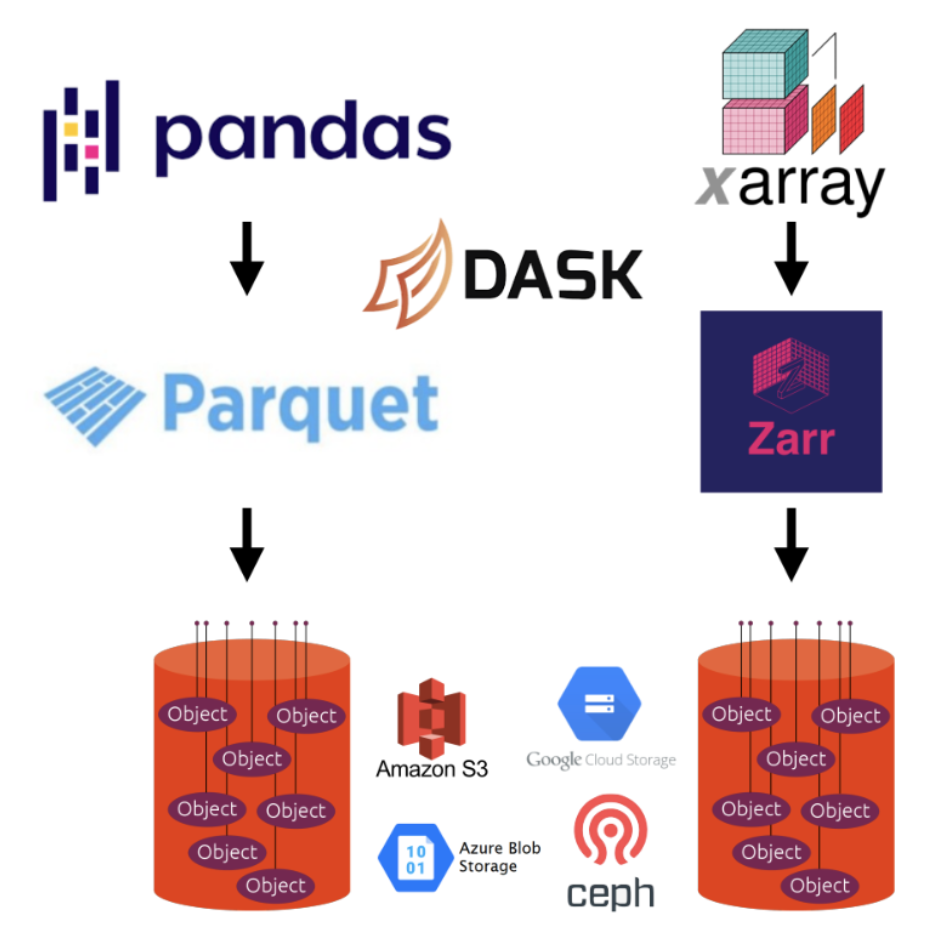
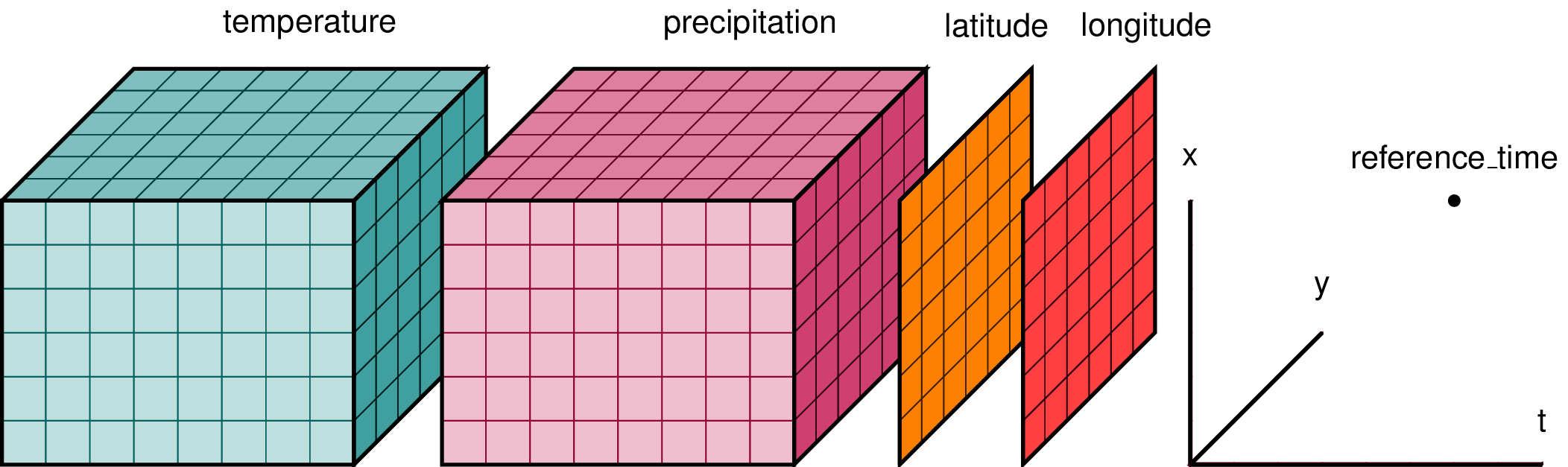
What is Zarr?
- Zarr is used to represent multidimensional raster data or “data cubes”. For example, weather data and climate models.
- Chunked, compressed, N-dimensional arrays.
- The metadata is stored external to the data files themselves. The data itself is often reorganized and compressed into many files which can be accessed according to which chunks the user is interested in.
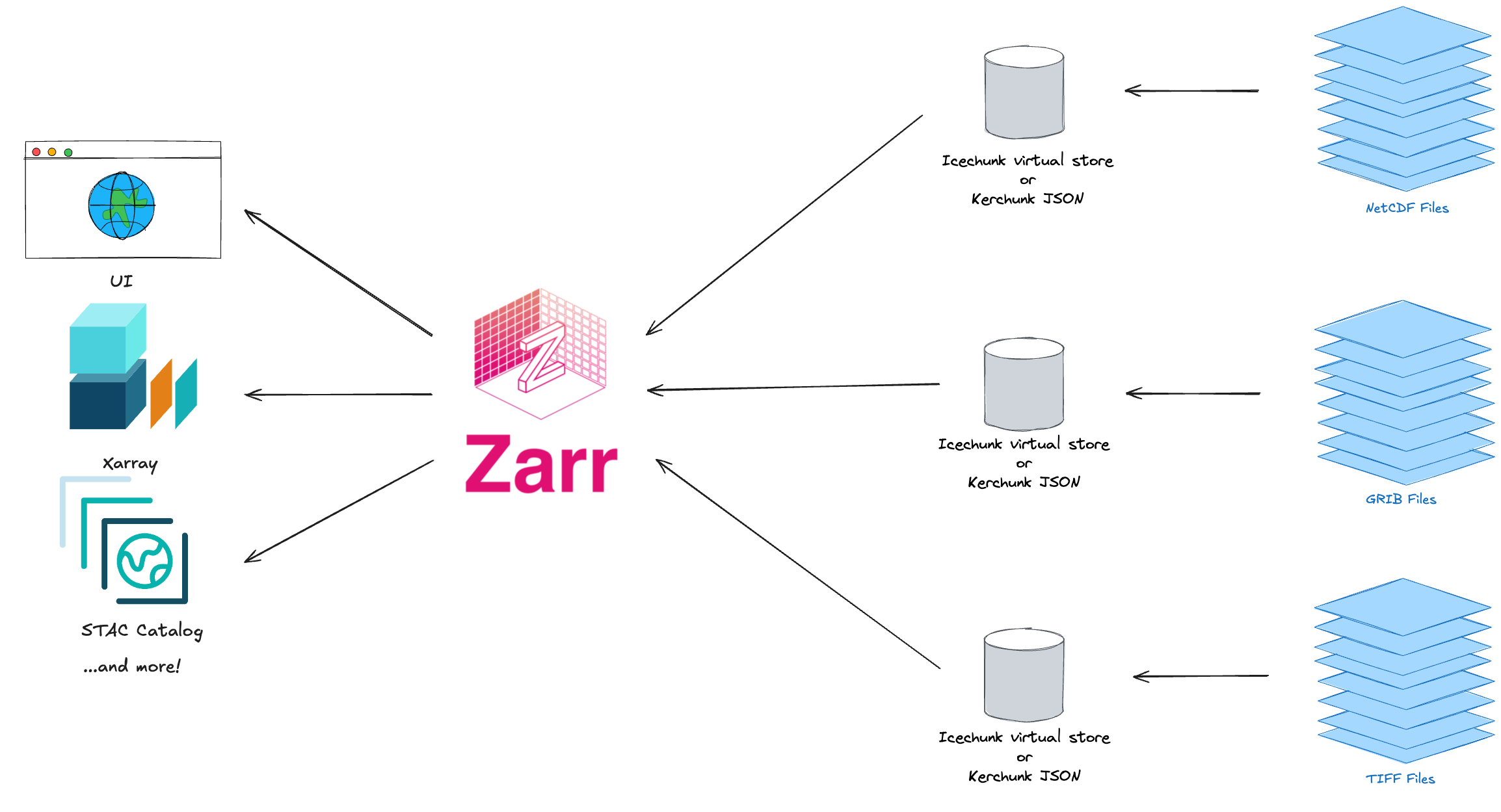
What is Virtual Zarr?
- Virtual Zarr stores include metadata along with references to data in archival file formats, such that you can leverage the benefits of partial and parallel reads for archives in NetCDF4, HDF5, GRIB2, TIFF and FITS. Kerchunk and Icechunk provide ways to persist Virtual Zarr stores on disk or in object stores.
COPC (Cloud-Optimized Point Clouds)

- Point clouds are a set of data points in space, such as gathered from LiDAR measurements.
- COPC is a valid LAZ file.
- Similar to COGs but for point clouds: COPC is just one file, but data is reorganized into a clustered octree instead of regularly gridded overviews.
- 2 key features:
- Support for partial decompression via storage of data in a series of chunks.
- Variable-length records (VLRs) can store application-specific metadata of any kind. VLRs describe the octree structure.
- Limitation: Not all attribute types are compatible.
FlatGeoBuf
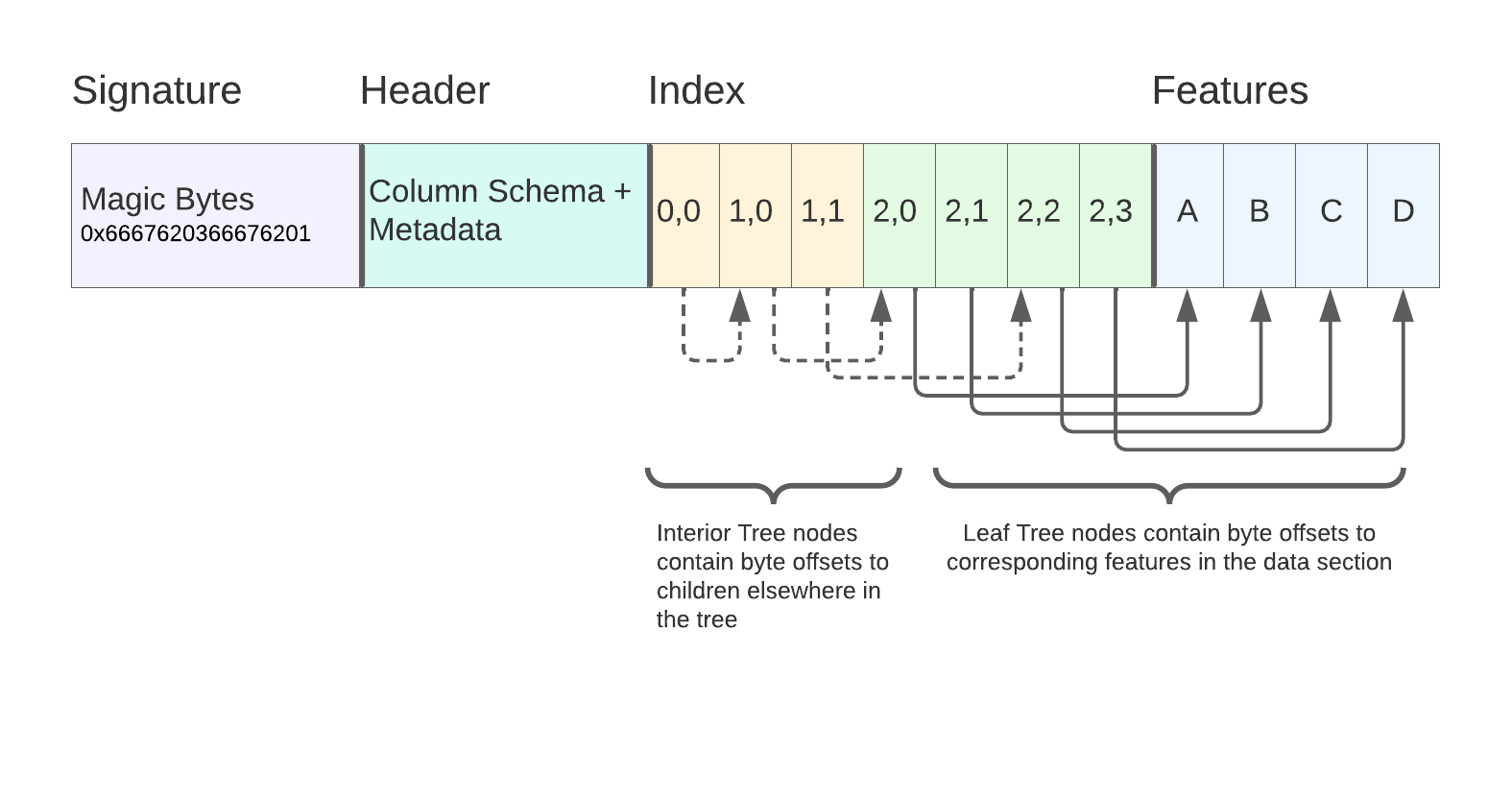
- Vector data is traditionally stored as rows representing points, lines, or polygons with an attribute table.
- FlatGeobuf is a binary encoding format for geographic data. Flatbuffers that hold a collection of Simple Features. Single-File.
- A row-based streamable-spatial index optimizes for remote reading.
- Developed with OGR compatibility in mind. Works with existing OGR APIs, e.g. python and R.
- Works with HTTP range requests, and has CDN compatibility.
- Limitation: Not compressed specifically to allow random reads.
- Learn more: https://github.com/flatgeobuf/flatgeobuf, Kicking the Tires: Flatgeobuf
Geoparquet
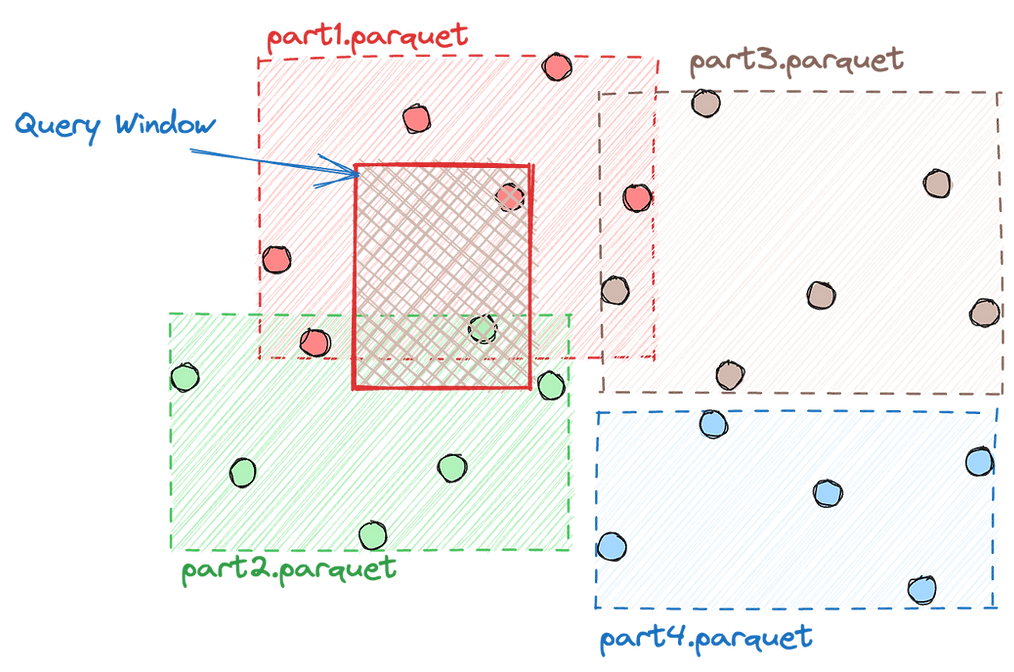
- Vector data is traditionally stored as rows representing points, lines, or polygons with an attribute table.
- GeoParquet defines how to store vector data in Apache Parquet, which is a columnar storage format (like many cloud data warehouses). “Give me all points with height greater than 10m”.
- GeoParquet is highly compressed.
- GeoParquet can be stored in a single- or multi-file store.
- GeoParquet support exists in GeoPandas and is supported in R with GeoArrow.
- GeoArrow provides the potential for cross language in-memory shared access.
- Specifications for spatial-indexing, projection handling, etc. are still in discussion.
- Learn more: https://github.com/opengeospatial/geoparquet