Cloud-Optimized Geospatial Formats Guide
Methods for Generating and Testing Cloud-Optimized Geospatial Formats
Why Cloud Optimize?
Geospatial data is experiencing exponential growth in both size and complexity. As a result, traditional data access methods, such as file downloads, have become increasingly impractical for achieving scientific objectives. With the limitations of these older methods becoming more apparent, cloud-optimized geospatial formats present a much-needed solution.
Cloud optimization enables efficient, on-the-fly access to geospatial data, offering several advantages:
- Reduced Latency: Subsets of the raw data can be fetched and processed much faster than downloading files.
- Scalability: Cloud-optimized formats are usually stored on cloud object storage, which is infinitely scalable. Object storage supports many parallel read requests when combined with metadata about where different data bits are stored, making it easier to work with large datasets.
- Flexibility: Cloud-optimized formats allow for high levels of customization, enabling users to tailor data access to their specific needs. Additionally, advanced query capabilities provide the freedom to perform complex operations on the data without downloading and processing entire datasets.
- Cost-Effectiveness: Reduced data transfer and storage needs can lower costs. Many of these formats offer compression options, which reduce storage costs.
If you want to provide optimized access to geospatial data, this guide is designed to help you understand the best practices and tools available for cloud-optimized geospatial formats.
Built for the Community, by the Community
There is no one-size-fits-all approach to cloud-optimized data. Still, the community has developed many tools for creating and assessing geospatial formats that should be organized and shared.
This guide provides the landscape of cloud-optimized geospatial formats and the best-known answers to common questions.
How to Get Involved
Read the Get Involved page if you want to contribute or modify content.
If you have a question or idea for this guide, please start a Github Discussion.
The Opportunity
Storing data in the cloud does not, on its own, solve geospatial’s data problems. Users cannot reasonably wait to download, store, and work with large files on their machines. Large volumes of data must be available via subsetting methods to access data in memory.
While it is possible to provide subsetting as a service, this requires ongoing maintenance of additional servers and extra network latency when accessing data (data has to go to the server where the subsetting service is running and then to the user). With cloud-optimized formats and the appropriate libraries, subsets of data can be accessed directly from an end user’s machine without introducing an additional server.
Regardless, users will access data over a network, which must be considered when designing the cloud-optimized format. Traditional geospatial formats are optimized for on-disk access via small internal chunks. A network introduces latency, and the number of requests must be considered.
As a community, we have arrived at the following cloud-optimized format pattern:
- Metadata or specification provides addresses for data blocks.
- Metadata is stored in a consistent format and location.
- All metadata can be loaded by a single read operation.
- Metadata or the format specification can be used by libraries to read subsets of data from the underlying file format. Subsetted access is facilitated via addressable chunks, internal tiling, or both.
These characteristics allow for parallelized and partial reading.
Data Type to Traditional to Cloud-Optimized Geospatial File Format Table
The diagram below depicts how some of the cloud-optimized formats discussed in this guide are cloud-optimized formats of traditional geospatial file formats.
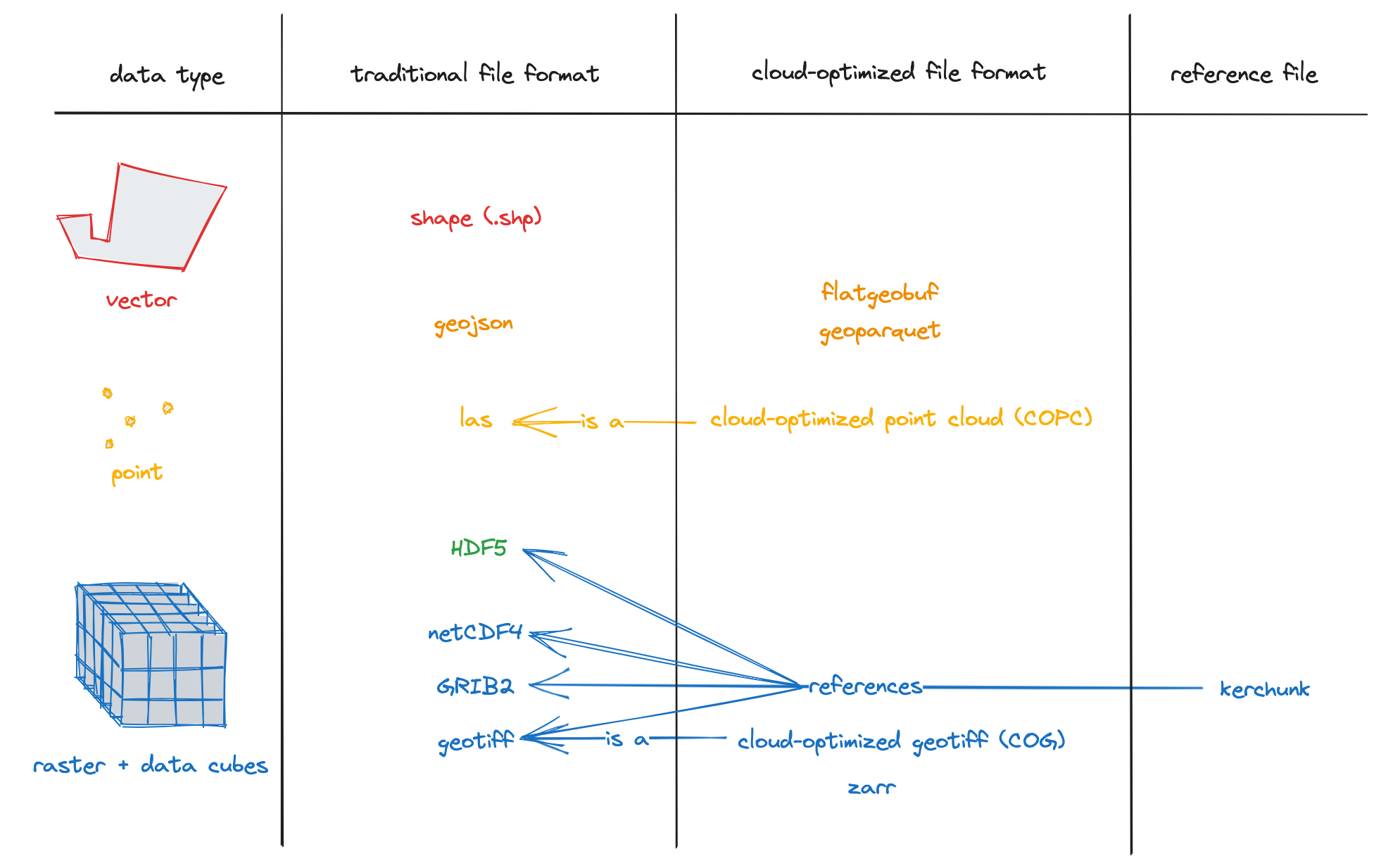
Notes:
- Some data formats cover multiple data types, specifically:
- GeoJSON can be used for vector and point cloud data.
- HDF5 can be used for point cloud data or data cubes (or both via groups).
- GeoParquet and FlatGeobuf can be used for vector data or point cloud data.
- LAS files are intended for 3D points, not 2D points (since COPC files are compressed LAS files, the same goes for COPC files).
- TopoJSON (an extension of GeoJSON that encodes topology) and newline-delimited GeoJSON are types of GeoJSON worth mentioning but have yet to be explicitly represented in the diagram.
- GeoTIFF and GeoParquet are geospatial versions of the non-geospatial file formats TIFF and Parquet, respectively. FlatGeobuf builds upon the non-geospatial flatbuffers serialization library (though flatbuffers is not a standalone file format).
Table of Contents
Running Examples
Most of the data formats covered in this guide have a Jupyter Notebook example that covers the basics of reading and writing the given format. At the top of each notebook is a link to an environment.yml file describing what libraries must be installed to run correctly. You can use Conda or Mamba (a successor to Conda with faster package installs) to install the environment needed to run the notebook.
Questions to Ask When Generating Cloud-Optimized Geospatial Data in Any Format
- What variable(s) should be included in the new data format?
- Will you create copies to optimize for different needs?
- What is the intended use case or usage profile? Will this product be used for visualization, analysis, or both?
- What is the expected access method?
- How much of your data is typically rendered or selected at once?
Our Supporters
Thank you to our supporters
This guide has been made possible through the support of:
![]()
![]()
![]()