GeoParquet
Guidelines for GeoParquet
GeoParquet
GeoParquet is an encoding for how to store geospatial vector data (point, lines, polygons) in Apache Parquet, a popular columnar storage format for tabular data.
Parquet has a wide ecosystem of tools and support; GeoParquet builds on this success by defining how to store geometries in the Parquet format. Because GeoParquet is not a separate format, any program that can read Parquet is able to load GeoParquet as well, even if it can’t make sense of the geometry information. This is very similar to how GeoTIFF layers geospatial information on top of the existing TIFF image standard.
The two main things that GeoParquet defines on top of Parquet are how to encode geometries in the geometry column and how to include metadata like the geometries’ Coordinate Reference System (CRS).
In September 2023, GeoParquet published a 1.0 release, and now any changes to the specification are expected to be backwards compatible.
Reading and writing GeoParquet has been supported in GDAL since version 3.5, and thus can be used in programs like GeoPandas and QGIS.
In GeoPandas use read_parquet and to_parquet to read and write GeoParquet, not read_file and to_file as one would use with most other formats. 1
Because GeoParquet stores geometries in standard Well-Known Binary (WKB), it supports any vector geometry type defined in the OGC Simple Features specification. This includes the standard building blocks of Point, LineString, Polygon, MultiPoint, MultiLineString, MultiPolygon, and GeometryCollection. A best practice is to store only geometries with the same type, as that allows readers to know which geometry type is stored without scanning the entire file.
Some of the sections below will discuss strengths of Parquet in general. Keep in mind that because GeoParquet is built on top of Parquet, GeoParquet inherits all of these strengths.
File layout
Parquet files are laid out differently than other tabular formats like CSV or FlatGeobuf, so it’s helpful to see a diagram:
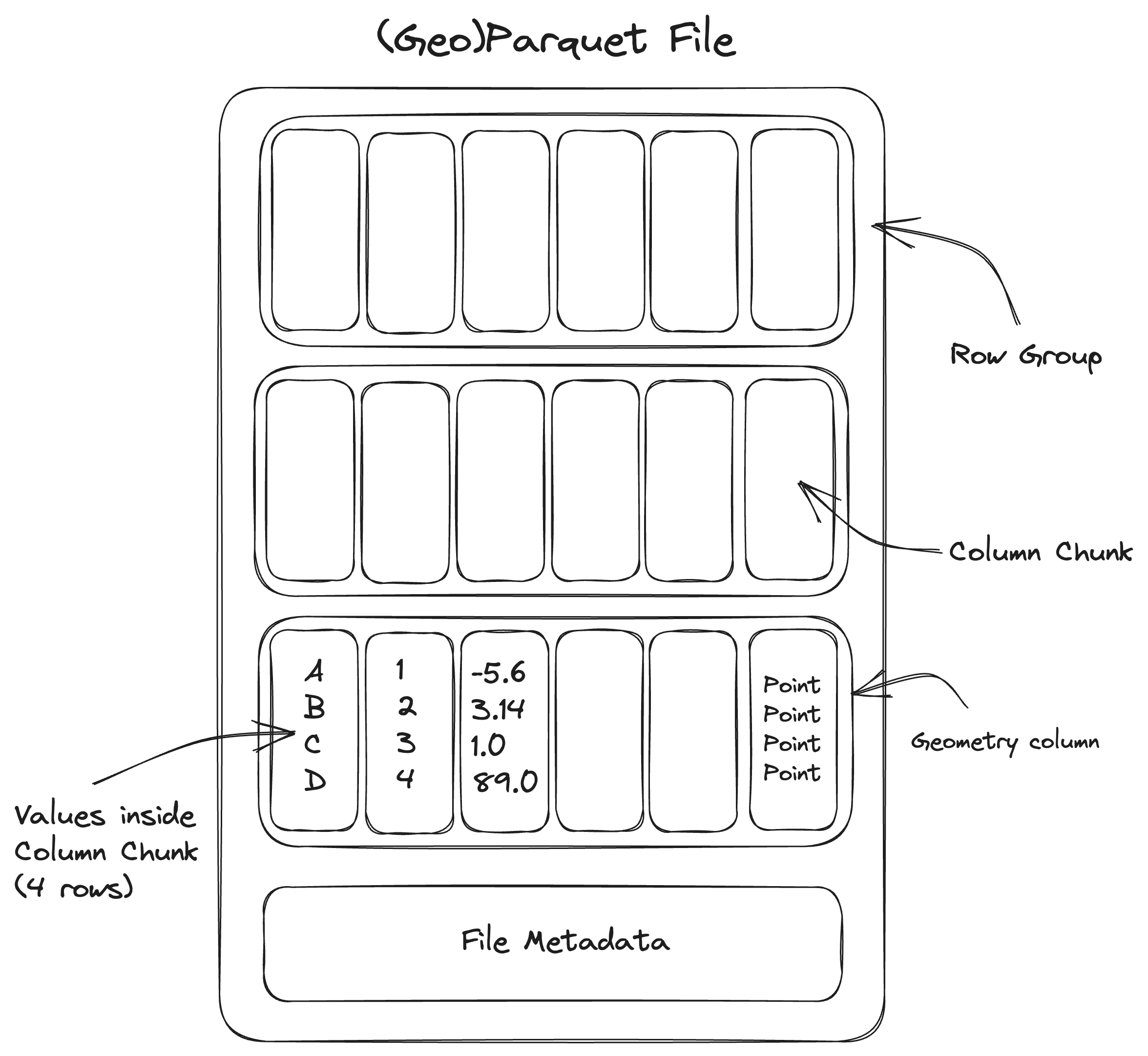
A Parquet file consists of a sequence of chunks called row groups. These are logical groups of columns with the same number of rows. A row group consists of multiple columns, each of which is called a column chunk. These are sequences of raw column values that are guaranteed to be contiguous in the file. All row groups in the file must have the same schema, meaning that the data type of each column must be the same for every row group.
A Parquet file includes metadata describing the internal chunking. This metadata includes the byte range of every column chunk in the dataset. This allows a Parquet reader to fetch any given column chunk once they have the file metadata.
The Parquet metadata also includes column statistics (the minimum and maximum value) for each column chunk. This means that if a user is interested in data where column “A” has values greater than 100, the Parquet reader can skip loading and parsing any column chunks where the maximum is known to be less than 100.
In Parquet, the metadata is located at the end of the file rather than at the beginning. This makes it much easier to write, as you don’t need to know how many total rows you have at the beginning, but makes it slightly harder to read. In practice, this is not too much more difficult to read: a Parquet reader first reads the end of the file, then makes reads for select columns.
Column-oriented
The bytes of each column are contiguous, instead of each row. This means that it’s easy to filter on columns — fetching all rows of a single column — but not possible to filter on individual rows.
Column filtering
Because Parquet is column-oriented, a Parquet reader can fetch only specific columns that the user is interested in.
Row group filtering
Because Parquet is internally chunked, Parquet can fetch only specific row groups that meet a specific filtering condition.
Note that row group filtering on a specific column tends to only work well if the Parquet file was sorted on that column when saved. Non-sorted columns tend to have random values, and so the column statistics won’t tend to filter out many row groups.
In general it’s only possible to optimize filtering row groups by one column. This is the biggest difference between file formats and databases. Databases can have multiple indexes on whatever columns you want, and then when you run a query, and it will use all of the indexes. But that’s why it’s hard to make databases work as cloud-native files, because if you have high latency, you don’t want to make lots of tiny fetches.
Internal compression by default
Parquet is internally compressed by default and Parquet compression is more efficient compared to other formats.
Compression algorithms are more effective when nearby bytes are more similar to each other. Data within a column tends to be much more similar than data across a row. Since Parquet is column-oriented, compression algorithms work better and result in smaller file sizes than a comparable row-based format.
It’s possible to have random access to one of the internal chunks inside the file at large, even though that chunk is compressed. Note that it isn’t possible to fetch partial data inside one chunk without loading and decompressing the entire chunk.
Geometries encoded as Well-Known Binary
For maximum compatibility with existing systems, geometries are stored as ISO-standard WKB. Most geospatial programs are able to read and write WKB.
No spatial index (yet!)
GeoParquet is a young specification, and spatial indices are not yet part of the standard. Future revisions of GeoParquet are expected to add support for spatial indexes.
One way around this is to store multiple GeoParquet files according to some region identifier, cataloging each file with the SpatioTemporal Asset Catalog (STAC) specification.
Multithreading support but no streaming
In a streaming download, you read bytes starting at the beginning of the file, progressing towards the end. In Parquet, this is not helpful because the metadata is in the footer of the file instead of the header.
Instead, we can replicate something similar to streaming by first fetching only the metadata region at the end of the file, and then making multiple requests for each internal chunk.
Files are immutable
Once written, a Parquet file is immutable. No modification or appending can happen to that Parquet file. Instead, create a new Parquet file.
Multi-file support
While at medium data sizes GeoParquet is most easily distributed as a single file, at large data sizes a single dataset is often split into multiple files. Sometimes multiple files can be easier to write, such as if the data is output from a distributed system.
A best practice when writing multiple files is to store a top-level metadata file, often named _metadata, with the metadata of all Parquet files in the directory. Without a top-level metadata file, a reader must read the Parquet footer of every individual file in the directory before reading any data. With a metadata file, a Parquet reader can read just that one metadata file, and then read the relevant chunks in the directory. For more information on this, read the “Partitioned Datasets” and “Writing _metadata and _common_metadata files” of the pyarrow documentation. As of August 2023, GeoPandas has no way to write multiple GeoParquet files out of the box, though you may be able to pass a * glob with multiple paths into geopandas.read_parquet.
Storing Parquet data in multiple files makes it possible to in effect append to the dataset by adding a new file to the directory, but you must be careful to ensure that the new file has the exact same data schema as the existing files, and if a top-level metadata file exists, it must be rewritten to reflect the new file.
Some elements of how to store GeoParquet-specific metadata in a multi-file layout have not yet been standardized.
Extensive type system
Parquet supports a very extensive type system, including nested types such as lists and maps (i.e. like a Python dict). This means that you can store a key-value mapping or a multi-dimensional array within an attribute column of a GeoParquet dataset.
References
Footnotes
As pointed out by GDAL developer Even Rouault, reading GeoParquet through GDAL is just as fast as reading through the
geopandas.read_parquetfunction if you’re using GDAL’s Arrow API. As of September 2023, this is not the default, so you need to opt into thepyogrioengine and opt into the Arrow API:import geopandas as gpd gpd.read_file("file.parquet", engine="pyogrio", use_arrow=True)It’s also necessary to note that the Python wheels distributed by pyogrio do not include the Arrow and Parquet drivers by default. In order to use the
pyogriodriver for a GeoParquet file, you need to compile from source when installing. You’ll need to have a GDAL installation version 3.6 or later (and built with Arrow and Parquet support, as seen byogrinfo --formats) on your computer already, and then you can buildpyogriofrom source with:↩︎pip install pyogrio --no-binary pyogrio